
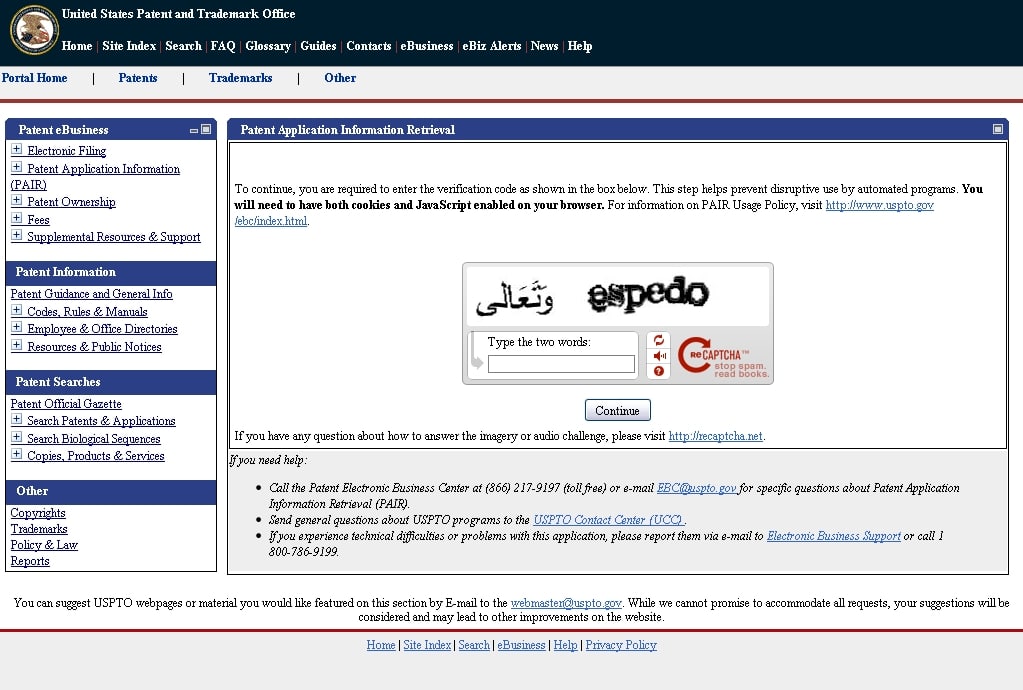
A Practitioner from a Leading U.S. Law Firm sent in a screen capture of the U.S. Patent and Trademark Office’s login screen for Patent Application Information Retrieval (PAIR) system.
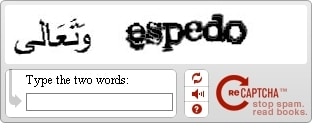
I find some interest that the site shows a bit of an international flavor in the use of Arabic characters. The full image is here: PAIR reCAPTCHA.
{kind=link}
Hello,
ReCAPTCHA images are generated automatically from scanned documents. It is possible that a CAPTCHA could contain non-English characters, such as Arabic letters or mathematical symbols.
If you receive an unreadable CAPTCHA on the Public PAIR site, simply click the refresh button next to the CAPTCHA text box.
If you have additional questions about the reCAPTCHA system, please contact Google using the following page: http://www.google.com/recaptcha/contact
If you have any other questions or concerns about the PAIR system, please let us know.
Thank you,
EBC
I also looked at the function of reCAPTCHA. A CAPTCHA is a program that can tell whether its user is a human or a computer. You’ve probably seen them — colorful images with distorted text at the bottom of Web registration forms. CAPTCHAs are used by many websites to prevent abuse from “bots,” or automated programs usually written to generate spam. No computer program can read distorted text as well as humans can, so bots cannot navigate sites protected by CAPTCHAs.
reCAPTCHA is a free CAPTCHA service that helps to digitize books, newspapers and old time radio shows at the same time! To archive written information, physical books are being photographically scanned, and then transformed into text using Optical Character Recognition (OCR).
reCAPTCHA improves the process of digitizing books by sending words that cannot be read by computers to the Web in the form of CAPTCHAs for humans to decipher. More specifically, each word that cannot be read correctly by OCR is placed on an image and used as a CAPTCHA.
Each new word that cannot be read correctly by OCR is given to a user in conjunction with another word for which the answer is already known. The user is then asked to read both words. If they solve the one for which the answer is known, the system assumes their answer is correct for the new one. The system then gives the new image to a number of other people to determine, with higher confidence, whether the original answer was correct.
About 200 million CAPTCHAs are solved by humans around the world every day, representing more than 150,000 hours of free work each day for Google Inc. (GOOG).
Hmmmmm…perhaps lawyers should join in the lawsuit against Google by the Authors Guild and the Association of American Publishers over the company’s digital reproduction of books.
The company’s plan to digitize every book ever published and make them widely available was derailed when a federal judge in New York rejected a $125 million legal settlement the company had worked out with groups representing authors and publishers. Google has already scanned some 15 million books.
[…] Patent practitioners unwittingly perform pro bono work for Google (Patent Baristas) […]